Difference Between Data Annotation and Labeling
For years, companies have been investing heavily in machine learning. In fact, machine learning is one of the most active research areas within the field of artificial intelligence (AI). The major goal of research in the field of machine learning is to create intelligent, self aware machines or computers capable of replicating human cognitive skills and acquiring knowledge on their own. So, understanding human learning well enough to reproduce aspects of that learning behavior in machines is a worthy scientific in itself. Every day humans are teaching computers to solve many new and exciting problems, such as playing your favorite playlist, showing driving directions to your nearest restaurant, and so on.
But still there are so many things computers cannot do, particularly in the context of understanding human behavior. Statistical methods have proved to be an effective means to approach these problems, but machine learning techniques work better when the algorithms are provided with pointers to what is relevant and meaningful in a dataset, rather than huge bulks of data. In the context of natural language processing, these pointers often come in the form of annotations – the art of labeling the data available in different formats. Data annotation and labeling are two fundamental elements of machine learning that help machines recognize images, text and videos.
What is Data Annotation?
Simply providing a computer with massive amounts of data and expecting it to learn to speak is not enough. The data has to be collected and presented in such a way that a computer can easily recognize patterns and inferences from the data. This is usually done by adding relevant metadata to a set of data. Any metadata tag used to mark up elements of the dataset is called an annotation over the input. So, in machine learning, data must be annotated, or to simply say, labeled, so that the system could easily recognize it. But, for the algorithms to learn effectively and efficiently, the annotation on data must be accurate and relevant to the job the computer is tasked with. Simply put, data annotation is the technique of labeling the data so that the machine could understand and memorize the input data.
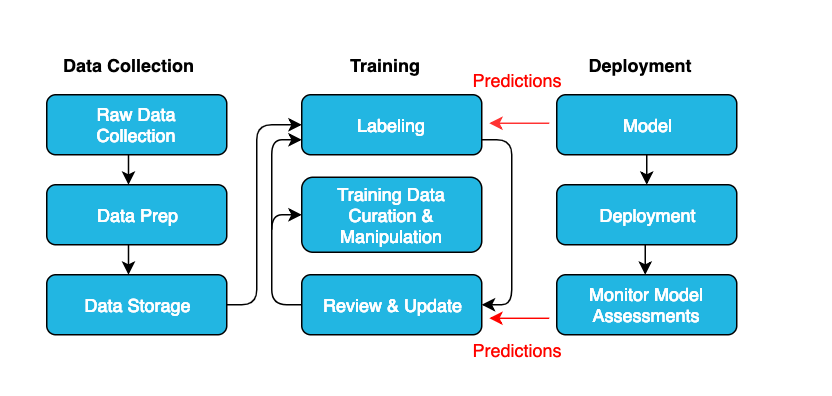
What is Data Labeling?
Data comes in many different forms such as text, images, audio, and video. To enrich the data so that the machine could recognize it through machine learning algorithms, the data needs to be labeled. Data labeling, as the name suggests, is the process of identifying raw data so that to attach meaning to different types of data in order to train a machine learning model. When the data is labeled, it is used for training advanced algorithms to recognize patterns in future. Labeling is basically tagging the data or adding metadata to make it more meaningful and informative so that machines can understand it and learn from it. For example, a label may indicate that an image contains a person or an animal, or an audio file is in which language, or to determine the kind of action performed in a video.
Difference between Data Annotation and Labeling
Meaning
– Both data labeling and annotation are the terms often used interchangeably to represent the process of tagging or labeling the data available in many different formats. Data annotation is basically the technique of labeling the data so that the machine could understand and memorize the input data using machine learning algorithms. Data labeling, also called data tagging, means to attach some meaning to different types of data in order to train a machine learning model. Labeling identifies a single entity from a set of data.
Purpose
– Labeling is a cornerstone of supervised machine learning and various industries still rely heavily on manually annotating and labeling their data. The labels are used to identify dataset features for NLP algorithms whereas data annotation can be used for visual based perception models. Labeling is more complicated than annotation. Annotation helps recognize relevant data through computer vision whereas labeling is used for training advanced algorithms to recognize patterns in future. Both processes need to be done with absolute accuracy to make sure something meaningful come out of the data so that to develop an NLP based AI model.
Applications
– Data annotation is a fundamental element in creating training data for computer vision. Annotated data is required to train machine learning algorithms to see the world as we humans see it. The idea is to make machines smart enough to learn, act and behave like humans, but where does this intelligence come from? The answer is data and lots and lots of it. Annotation is a process used in supervised machine learning for training data sets to help machines understand and recognize the input data and act accordingly. Labeling is used to identify key features present in the data while minimizing human involvement. The real world use cases include NLP, audio and video processing, computer visions, etc.
Data Annotation vs. Data Labeling: Comparison Chart

Summary
Annotation is a process used in supervised machine learning for training data sets to help machines understand and recognize the input data and act accordingly. Labeling is used to identify key features present in the data while minimizing human involvement. Labeling is a cornerstone of supervised machine learning and various industries still rely heavily on manually annotating and labeling their data. Because poor labeling may lead to compromised AI, labeling or annotating must be done accurately so that they could be used for AI applications.
- Difference Between Caucus and Primary - June 18, 2024
- Difference Between PPO and POS - May 30, 2024
- Difference Between RFID and NFC - May 28, 2024
Search DifferenceBetween.net :
Leave a Response
References :
[0]Mitchell, Tom M. et al. Machine Learning: A Guide to Current Research. Berlin, Germany: Springer, 2012. Print
[1]Michalski, Ryszard S.et al. Machine Learning: An Artificial Intelligence Approach (Volume I). Amsterdam, Netherlands: Elsevier, 2014. Print
[2]Pustejovsky, James and Amber Stubbs. Natural Language Annotation for Machine Learning: A Guide to Corpus-Building for Applications. California, United States: O'Reilly Media, Inc., 2012. Print
[3]Morisio, Maurizio et al. Product-Focused Software Process Improvement: 21st International Conference, PROFES 2020, Turin, Italy, November 25–27, 2020, Proceedings. Berlin, Germany: Springer, 2020. Print
[4]Image credit: https://commons.wikimedia.org/wiki/File:Screen-Shot-2019-02-06-at-11.25.36-AM.png
[5]Image credit: https://upload.wikimedia.org/wikipedia/commons/8/89/XO_Annotated_Motherboard.png