Difference Between Hadoop and Cassandra
With massive amounts of data that get generated at a very high speed by a massive explosion of Internet of Things and increasing use of social media, the capability to store and analyze these massive amounts of data has increased. Hadoop is one of the sophisticated tools designed to handle such large amounts of data, which is often referred to as Big Data. Cassandra is yet another highly scalable database that is easy to deploy and manage. But which is the best choice – Hadoop or Cassandra?
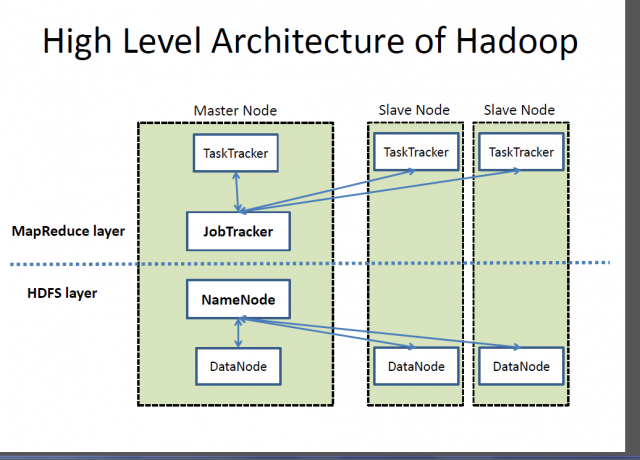
What is Hadoop?
Apache Hadoop is the de facto framework for processing and storing large volumes of data, which is often referred to as “Big Data”. Hadoop is the cornerstone of all Big Data solutions. A project by the Apache Software Foundation, Hadoop is a large-scale distributed processing system designed to distribute and process large amounts of data across the nodes in the cluster. It is not aimed at replacing the traditional database systems; in fact, Hadoop makes it easier to use relational databases by speeding up operations related to large data sets. Hadoop is based on the famous MapReduce programming model suitable for processing of huge data sets, distributed across a cluster of nodes, in parallel. The Hadoop Distributed File System (HDFS) is the data storage and processing filesystem for Hadoop that runs on commodity hardware and provides parallel, streaming access to large quantities of data.
What is Cassandra?
Apache Cassandra is an open-source, fully distributed, column-oriented database that offers superior scalability and fault tolerance to traditional single master databases. Cassandra is a non-relational database, also called a NoSQL database that bases its distribution design on Amazon’s Dynamo and its data model on Google’s Bigtable – a high performance NoSQL database built on the proprietary Google storage technologies for large database infrastructures. It is a distributed management system designed to handle large amounts of structured data across commodity servers. Compared to other popular distributed databases like HBase, Voldermort, and Riak, Apache Cassandra offers a robust and expressive interface for modeling and querying data. The best part about Cassandra is that it is distributed meaning it is capable of running on multiple machines.
Difference between Hadoop and Cassandra
Definition
– Hadoop is an Apache open-source framework written in Java that is designed to handle large amounts of data which needs to be processed at scale when you process a lot of data at the same time in a streaming fashion or in a batch-like fashion. Apache Cassandra, on the other hand, is a highly scalable, fully distributed database designed to handle large amounts of structured data across commodity servers. Apache Cassandra offers a robust and expressive interface for modeling and querying data.
Deployment
– Hadoop is a scalable framework that is designed to be deployed on low-cost hardware. HDFS storage is spread across a cluster of nodes; a single large file could be stored across multiple nodes in the cluster. It is deployed in a single data center, but they are all co-located geographically with each other. Cassandra, on the other hand, is deployed in a very distributed fashion as a cluster of instances that are all aware of each other. Data can be read or written to any instance in the cluster, referred to as a node, which will forward the request to the instance where the data belongs to.
Framework
– Apache Hadoop is a big data processing framework based on the famous MapReduce programming model suitable for processing of huge data sets, distributed across a cluster of nodes, in parallel. It is a distributed processing system designed to distribute and process large amounts of data across the nodes in the cluster. Cassandra, on the other hand, is a fully distributed NoSQL database that offers a uniquely robust and expressive interface for modeling and querying data. It is not like the traditional database systems; in fact, it stores data in key value pair. Unlike Hadoop, Cassandra is mainly used for real-time data processing.
Data Format
– Hadoop can work with just any kind of data in a variety of formats, whether it’s structured, semi-structured, or un-structured, and whatever you can possibly think of – images, JSON, XML, and so on. Cassandra, on the other hand, is a distributed management system designed to handle large amounts of structured data across commodity servers. On top of it, Cassandra does not support images.
Architecture
– Hadoop follows a master slave architecture consisting of master nodes and slave nodes. The NameMode is the master node and the DataNodes are the slave nodes. Usually, a DataNode daemon runs on each slave mode and manages the storage attached to each DataNode. The HDFS can be deployed on a wide range of machines running Java. Cassandra, on the other hand, stores data on different nodes with a peer-to-peer distributed system, making it easier to operate and maintain a decentralized store than a master/slave store because all nodes are the same.
Hadoop vs. Cassandra: Comparison Chart

Summary
Hadoop is the cornerstone of big data solutions that offers a cutting-edge platform to store and analyze massive amounts of data sets and improve upon the traditional relational database managements systems. Apache Hadoop provides a fault-tolerant, distributed framework for storage and processing of very large data sets across clusters of commodity. Cassandra is the leading NoSQL database that takes the best technological advances from the Dynamo and Bigtable papers to handle large amounts of structured data across commodity servers. Besides, Cassandra is great for speedy online transactions while Hadoop is ideal for faster storage and retrieval of data.
- Difference Between Caucus and Primary - June 18, 2024
- Difference Between PPO and POS - May 30, 2024
- Difference Between RFID and NFC - May 28, 2024
Search DifferenceBetween.net :
Leave a Response
References :
[0]Image credit: https://commons.wikimedia.org/wiki/File:Helenos_for_Apache_Cassandra.PNG
[1]Image credit: https://commons.wikimedia.org/wiki/File:Hadoop-HighLevel_hadoop_architecture-640x460.png
[2]Venner, Jason, et al. Pro Apache Hadoop. New York, United States: Apress, 2014. Print
[3]Vohra, Deepak. Practical Hadoop Ecosystem: A Definitive Guide to Hadoop-Related Frameworks and Tools. New York, United States: Apress, 2016. Print
[4]Neeraj, Nishant. Mastering Apache Cassandra. Birmingham, United Kingdom: Packt Publishing, 2013. Print
[5]Brown, Mat. Learning Apache Cassandra. Birmingham, United Kingdom: Packt Publishing, 2015. Print